Natural Language Processing and LLMs Training









Natural Language Processing and LLMs Training
Natural Language Processing and LLMs E-Learning Training Gecertificeerde docenten Quizzen Assessments Tips trucs en Certificaat.
Lees meer- Kortingen:
-
- Koop 2 voor €194,04 per stuk en bespaar 2%
- Koop 3 voor €192,06 per stuk en bespaar 3%
- Koop 4 voor €190,08 per stuk en bespaar 4%
- Koop 5 voor €188,10 per stuk en bespaar 5%
- Koop 10 voor €178,20 per stuk en bespaar 10%
- Koop 25 voor €168,30 per stuk en bespaar 15%
- Koop 50 voor €158,40 per stuk en bespaar 20%
- Beschikbaarheid:
- Op voorraad
- Levertijd:
- Voor 17:00 uur besteld! Start vandaag. Gratis Verzending.
- Award Winning E-learning
- De laagste prijs garantie
- Persoonlijke service van ons deskundige team
- Betaal veilig online of op factuur
- Bestel en start binnen 24 uur












Natural Language Processing and LLMs E-Learning Training
Duik in onze Natural Language Processing en LLMs Training serie. Begin met de Fundamentals of NLP om een sterke basis te leggen in tekstvoorverwerking, representatie en classificatie. Ga verder met Deep Learning voor NLP om geavanceerde technieken te beheersen, en ontdek LLMs met geavanceerde aandachtmechanismen en transformerarchitecturen. Leer LLMs toe te passen voor taken zoals taalvertaling en tekstsamenvattingen. Boek nu en blijf aan de voorhoede van NLP-innovatie!
Deze Learning Kit met meer dan 21 leeruren is verdeeld in drie sporen:
Cursusinhoud
Track 1: Natural Language Processing
This track provides a comprehensive introduction to the core concepts and techniques in NLP. Beginning with an overview of NLP components, including natural language understanding (NLU) and natural language generation (NLG), the track explores common NLP tasks such as speech recognition and sentiment analysis. Participants will then delve into preprocessing text data using NLTK, covering essential techniques such as text cleaning, sentence segmentation, and parts-of-speech tagging. Additionally, the track explores methods for representing text in numeric format, including one-hot encoding and TF-IDF encoding, before introducing classification models for text data. Through hands-on exercises and practical examples, participants will learn how to build classification models using rule-based approaches, Naive Bayes classification, and other techniques, leveraging tools like Scikit-learn pipelines and grid search for optimal performance. Participants will then harness the power of TensorFlow for building deep learning models, followed by an in-depth exploration of text preprocessing techniques such as normalization, tokenization, and text vectorization. Through hands-on exercises, learners will delve into the intricacies of modeling building, training, and evaluation for text classification tasks, encompassing binary classification and multi-class classification using dense neural networks, recurrent neural networks (RNNs), and RNNs with LSTM cells. The track will also cover hyperparameter tuning using the Keras tuner to optimize model performance. Participants will gain proficiency in leveraging word embeddings, including training embedding layers in models, exploring and visualizing embeddings, and utilizing embeddings for tasks like word and semantic similarity. Moreover, the track will explore text translation using RNNs and demonstrate the utilization of pre-trained models for semantic textual similarity, providing participants with a comprehensive understanding of cutting-edge NLP techniques in the context of deep learning.
Courses:
Fundamentals of NLP: Introducing Natural Language Processing
Course: 48 Minutes
- Course Overview
- Introducing Natural Language Processing (NLP) with NLTK and spaCy
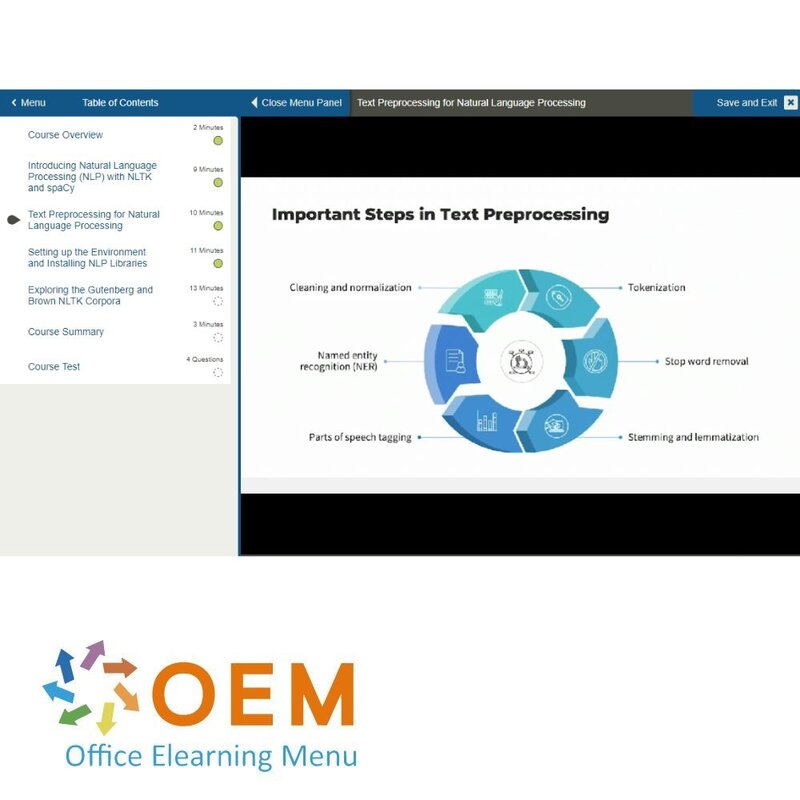
- Text Preprocessing for Natural Language Processing
- Setting up the Environment and Installing NLP Libraries
- Exploring the Gutenberg and Brown NLTK Corpora
- Course Summary
Fundamentals of NLP: Preprocessing Text Using NLTK and SpaCy
Course: 1 Hour, 57 Minutes
- Course Overview
- Implementing Word and Sentence Tokenization with NLTK
- Implementing Word and Sentence Tokenization Using SpaCy
- Performing Stop Word Removal Using NLTK
- Performing Stopword Removal Using SpaCy
- Understanding WordNet Synsets
- Computing Word Similarity Using WordNet
- Understanding Hypernyms, Hyponyms, Antonyms, Meronyms, and Holonyms
- Performing Stemming Using NLTK
- Performing Lemmatization Using NLTK
- Performing Lemmatization Using SpaCy
- Performing Parts of Speech Tagging and Named Entity Recognition
- Course Summary
Fundamentals of NLP: Rule-based Models for Sentiment Analysis
Course: 46 Minutes
- Course Overview
- Sentiment Analysis Introduction
- Loading and Understanding Review Data
- Cleaning and Visualizing Review Data
- Performing Sentiment Analysis Using VADER
- Performing Sentiment Analysis Using TextBlob
- Course Summary
Fundamentals of NLP: Representing Text as Numeric Features
Course: 2 Hours
- Course Overview
- One-hot Encoding to Represent Text in Numeric Form
- Utilizing One-hot Encoding to Represent Text Data
- Performing One-hot Encoding Using the Count Vectorizer
- Frequency-based Encodings to Represent Text in Numeric Form
- Perform Count Vector Encoding Using the Count Vectorizer
- Working with Bag-of-Words and Bag-of-N-grams Representation
- Perform TF-IDF Encoding to Represent Text Data
- Exploring the Product Reviews Dataset
- Building a Classification Model Using Count Vector Encoding
- Comparing Models Trained with Stemmed Words and Stopword Removed
- Classifying Text Using Frequency Filtering and TF-IDF Encodings
- Training Classification Models Using Bag of N-grams
- Training Classification Models with N-grams and TF-IDF Representation
- Course Summary
Fundamentals of NLP: Word Embeddings to Capture Relationships in Text
Course: 1 Hour, 1 Minutes
- Course Overview
- Word Embeddings to Represent Text in Numeric Form
- Generating Word2Vec Embeddings
- Training a Classification Model Using Word2Vec Embeddings
- Working with Pre-trained GloVe Embeddings
- Training a Classification Model Using GloVe Embeddings
- Training Different Classification Models for Sentiment Analysis
- Course Summary
Natural Language Processing Using Deep Learning
Course: 1 Hour, 55 Minutes
- Course Overview
- Deep Learning with TensorFlow and Keras
- Loading and Exploring a Text Dataset
- Cleaning and Visualizing Data
- Generating Count Vector Representations
- Training a Deep Neural Network (DNN) Classification Model
- TF-IDF Representations Using the TextVectorization Layer
- Training a DNN Using TF-IDF Vectors
- Visualizing the Results of TensorFlow Callbacks
- Loading and Preprocessing Data for Sentiment Analysis
- Training a DNN Using Word Embeddings
- Training a DNN Using Pretrained GloVe Word Embeddings
- Using a Convolutional Neural Network (CNN) for Sentiment Analysis
- Course Summary
Using Recurrent Networks For Natural Language Processing
Course: 1 Hour, 15 Minutes
- Course Overview
- Recurrent Neural Networks (RNNs) for Sequential Data
- Visualizing Word Embeddings Using the Embedding Projector Plug-in
- Setting up Word Vector Representations for Training
- Training an RNN for Sentiment Analysis
- Training an RNN with LSTM and Bidirectional LSTM Layers
- Performing Hyperparameter Tuning
- Course Summary
Using Out-of-the-Box Transformer Models for Natural Language Processing
Course: 1 Hour, 30 Minutes
- Course Overview
- Transfer Learning
- Using Pre-trained Embeddings from the TensorFlow Hub
- Attention-based Models and Transformers
- Performing Subword Tokenization with WordPiece
- Using the FNet Encoder for Sentiment Analysis
- Using the Universal Sentence Encoder (USE) for Semantic Textual Similarity
- Structuring Data for Sentence Similarity Prediction Using BERT
- Using a Fine-tuned BERT Model for Sentence Classification
- Course Summary
Attention-based Models and Transformers for Natural Language Processing
Course: 2 Hours, 20 Minutes
- Course Overview
- Language Translation Models and Attention
- Preparing Data for Language Translation
- Configuring the Encoder-Decoder Architecture
- Defining the Loss and Accuracy for the Translation Model
- Training Validation and Prediction Using Encoder and Decoder
- Setting up the Decoder Architecture with Attention Layer
- Generating Translations Using the Attention Model
- The Transformer Architecture: Part I
- The Transformer Architecture: Part II
- Using Query, Key, and Value in the Attention Mechanism
- Structuring Translations for Input to a Transformer Model
- Setting up the Encoder and Decoder in the Transformer Architecture
- Training the Transformer Model and Using It for Predictions
- Course Summary
Track 2: Architecting LLM for your Technical solutions
This track is designed to immerse participants in the transformative world of Large Language Models (LLMs), leveraging state-of-the-art techniques powered by deep learning and attention mechanisms. Participants will gain a deep understanding of attention mechanisms and the revolutionary transformer architecture, including self-attention and multi-head attention mechanisms. Through hands-on exercises and practical demonstrations, learners will explore the foundational concepts of LLMs and delve into implementing translation models using transformers. Moreover, participants will be introduced to the Hugging Face platform, learning to leverage pre-trained models from the Hugging Face library and fine-tune them for specific use cases. From text classification to language translation, question answering, text summarization, and natural language generation, participants will acquire the skills needed to harness the full potential of LLMs for a wide range of NLP tasks.
Courses:
NLP with LLMs: Working with Tokenizers in Hugging Face
Course: 2 Hours, 18 Minutes
- Course Overview
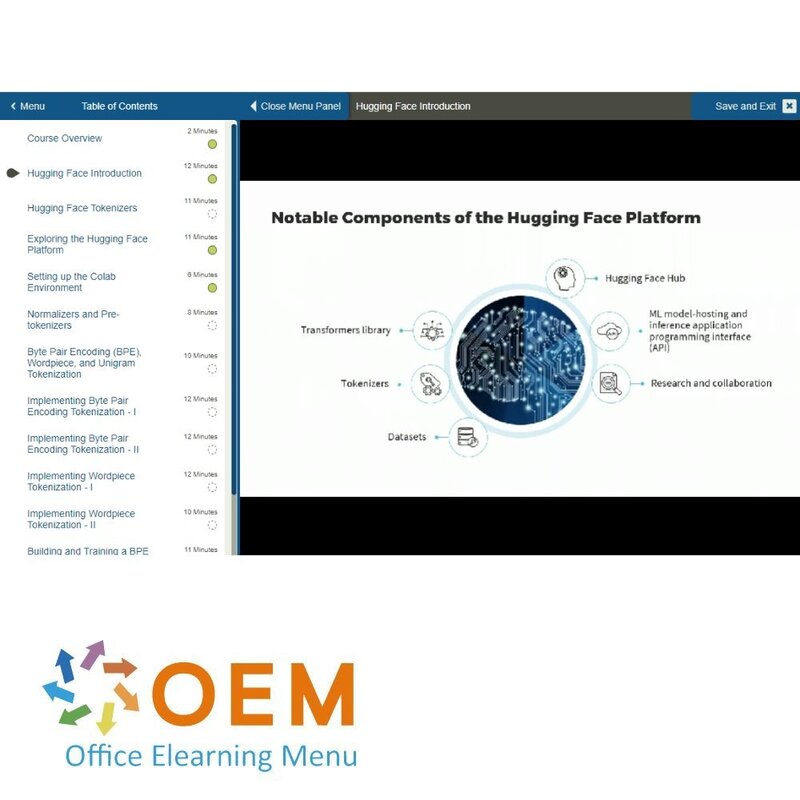
- Hugging Face Introduction
- Hugging Face Tokenizers
- Exploring the Hugging Face Platform
- Setting up the Colab Environment
- Normalizers and Pre-tokenizers
- Byte Pair Encoding (BPE), Wordpiece, and Unigram Tokenization
- Implementing Byte Pair Encoding Tokenization - I1
- Implementing Byte Pair Encoding Tokenization - II1
- Implementing Wordpiece Tokenization - I1
- Implementing Wordpiece Tokenization - II
- Building and Training a BPE Tokenizer
- Configuring the Normalizer and Pre-tokenizer for Wordpiece Tokenization
- Building and Training a Wordpiece Tokenizer
- Course Summary
NLP with LLMs: Hugging Face Classification, QnA, & Text Generation Pipelines
Course: 1 Hour, 50 Minutes
- Course Overview
- Hugging Face Pipelines
- Performing Zero-shot Classification
- Performing Sentiment Analysis Using DistilBERT
- Detecting Emotion and Sentiment Analysis on Financial Data
- Performing Named Entity Recognition (NER) with a Fine-tuned BERT Model
- Performing Named Entity Recognition Using Tokenizer and Model
- Performing Question Answering Using Pipelines
- Performing Question Answering Using Tokenizer and Model
- Performing Greedy Search and Beam Search for Text Generation Using GPT
- Generating Text Using Sampling
- Performing Mask Filling Using Variations of the BERT Model
- Course Summary
NLP with LLMs: Language Translation, Summarization, & Semantic Similarity
Course: 1 Hour, 29 Minutes
- Course Overview
- Performing Language Translation Using Two Variants of the T5 Model
- Performing Language Translation Using the M2M 100 and Opus Models
- Summarizing Text Using a BART Model and a T5 Model
- Loading Data and Cleaning Text for Summarization
- Evaluating Summaries Using ROUGE Scores
- Computing Semantic Textual Similarity Using Sentence Transformers
- Performing Clustering Using Sentence Embeddings
- Computing Embeddings and Similarity Using the Tokenier and Model
- Course Summary
NLP with LLMs: Fine-tuning Models for Classification & Question Answering
Course: 1 Hour, 34 Minutes
- Course Overview
- Loading Data and Creating a Dataset for Fine-tuning
- Setting up for Fine-tuning a BERT Classifier
- Fine-tuning a BERT Model and Pushing to Hugging Face Hub
- Getting Predictions from a Fine-tuned Model
- Structuring Text for Named Entity Recognition
- Aligning NER Tags to Match Subword Tokenization
- Fine-tuning a BERT Model for Named Entity Recognition
- Dealing with Long Contexts for Question Answering
- Structuring QnA Data in the Right Format for Fine Tuning
- Fine-tuning a DistilBERT Model for Question Answering
- Course Summary
NLP with LLMs: Fine-tuning Models for Language Translation, & Summarization
Course: 1 Hour, 38 Minutes
- Course Overview
- Processing and Structuring Data for Causal Language Modeling (CLM)
- Fine-tuning a DistilGPT-2 Model for Causal Language Modeling
- Fine-tuning a DistilRoBERTa Model for Masked Language Modeling (MLM)
- Preparing the Translation Data for Fine-tuning
- Preprocessing Text and Computing Metrics for Translation
- Fine-tuning the T5-small Model for English to Spanish Translation
- Loading and Visualizing Summarization Data
- Evaluating the Baseline Performance of the Pretrained T5-small Model
- Fine-tuning the T5-small Model for Summarization
- Comparing the Fine-tuned Model's Performance with the Baseline Model
- Course Summary
Assessment:
- Final Exam: Architecting LLMs for Your Technical Solutions
| Taal | Engels |
|---|---|
| Kwalificaties van de Instructeur | Gecertificeerd |
| Cursusformaat en Lengte | Lesvideo's met ondertiteling, interactieve elementen en opdrachten en testen |
| Lesduur | 21:35 uur |
| Assesments | De assessment test uw kennis en toepassingsvaardigheden van de onderwerpen uit het leertraject. Deze is 365 dagen beschikbaar na activering. |
| Online Virtuele labs | Ontvang 12 maanden toegang tot virtuele labs die overeenkomen met de traditionele cursusconfiguratie. Actief voor 365 dagen na activering, beschikbaarheid varieert per Training. |
| Online mentor | U heeft 24/7 toegang tot een online mentor voor al uw specifieke technische vragen over het studieonderwerp. De online mentor is 365 dagen beschikbaar na activering, afhankelijk van de gekozen Learning Kit. |
| Voortgangsbewaking | Ja |
| Toegang tot Materiaal | 365 dagen |
| Technische Vereisten | Computer of mobiel apparaat, Stabiele internetverbindingen Webbrowserzoals Chrome, Firefox, Safari of Edge. |
| Support of Ondersteuning | Helpdesk en online kennisbank 24/7 |
| Certificering | Certificaat van deelname in PDF formaat |
| Prijs en Kosten | Cursusprijs zonder extra kosten |
| Annuleringsbeleid en Geld-Terug-Garantie | Wij beoordelen dit per situatie |
| Award Winning E-learning | Ja |
| Tip! | Zorg voor een rustige leeromgeving, tijd en motivatie, audioapparatuur zoals een koptelefoon of luidsprekers voor audio, accountinformatie zoals inloggegevens voor toegang tot het e-learning platform. |
Er zijn nog geen reviews geschreven over dit product.
OEM Office Elearning Menu Top 2 in ICT-trainingen 2024!
OEM Office Elearning Menu is trots op de tweede plaats in de categorie ICT-trainingen 2024 bij Beste Opleider van Nederland (Springest/Archipel). Dank aan al onze cursisten voor hun vertrouwen!
Beoordelingen
Er zijn nog geen reviews geschreven over dit product.





